
.
livello medio
.
ARGOMENTO: SUBACQUEA
PERIODO: XXI SECOLO
AREA: DIDATTICA
parole chiave: computer subacquei, algoritmi, conservatività
 Abbiamo parlato dell’atteggiamento molto ostile che alcuni subacquei, specialmente tra i più esperti e tecnici, hanno nei confronti del computer subacqueo, valutando le motivazioni delle critiche più frequenti, cercando di verificarne la fondatezza sulla base di considerazioni più oggettive e misurabili possibili. Abbiamo concluso l’articolo lasciando un punto ancora aperto, sintetizzato dalla seguente affermazione ricorrente:
Abbiamo parlato dell’atteggiamento molto ostile che alcuni subacquei, specialmente tra i più esperti e tecnici, hanno nei confronti del computer subacqueo, valutando le motivazioni delle critiche più frequenti, cercando di verificarne la fondatezza sulla base di considerazioni più oggettive e misurabili possibili. Abbiamo concluso l’articolo lasciando un punto ancora aperto, sintetizzato dalla seguente affermazione ricorrente:
| non ho mai dato retta ad un computer e ho sempre utilizzato questa o quella metodologia empirica, oppure dettata dall’esperienza personale, e non ho mai avuto incidenti |
Qui la faccenda si fa piuttosto delicata
Chiunque di noi può evitare l’uso del computer senza rinunciare alla sicurezza, semplicemente dotandosi di tabelle o pianificazioni da esse derivate che lo mettano al sicuro in ogni caso. Ma sembra stiano prendendo piede criteri o algoritmi decompressivi sperimentali stabiliti in autonomia, basati su esperienza personale, letture, opinioni scambiate sul web ed elaborazione di tabelle o algoritmi esistenti. Naturalmente ognuno è responsabile delle proprie azioni, e chi è particolarmente esperto o disposto a assumere rischi calcolati effettuando immersioni estreme o affidandosi a metodologie non molto sperimentate, è naturalmente è titolato a farlo proprio in virtù della propria propensione al rischio e consapevolezza. Ma queste sono considerazioni valide per pionieri o sperimentatori, e non per il subacqueo ricreativo o sportivo. La criticità di una simile affermazione sta nel ritenere che non aver mai subito incidenti utilizzando un qualche metodo empirico o basato sulla propria esperienza personale sia sufficiente a dimostrarne la validità e sicurezza.
Non è così, per ragioni statistiche
La ragione di fondo è che quando un evento è raro (l’incidente embolico, nel nostro caso), il numero di immersioni significativo per stimare il reale tasso di rischio di tale metodologia è alto, molto alto. Una vita intera di immersioni senza incidenti non è sufficiente a validare un metodo o modello. Come affermato al termine dell’articolo precedente, l’esperienza personale e la preparazione sono sempre fattori molto importanti, ma non al punto prevalere sulle conclusioni di centri di ricerca di tutto il mondo che impiegano le proprie risorse per migliorare la conoscenza della fisiologia iperbarica e incrementare la sicurezza in immersione.

Abbiamo già avuto occasione di raccontare come la storia dello sviluppo delle tabelle decompressive, a partire da quelle più famose della marina degli Stati Uniti d’America per arrivare a tutte le tabelle oggi disponibili, sia stata lunga, difficile e travagliata, e ha richiesto molto più tempo ed impegno nella fase di verifica e validazione che nella fase teorica di implementazione. Questo perché fissare dei criteri e delle ipotesi in fase teorica è più agevole che misurare, o meglio stimare, il tasso di rischio che accettiamo di correre impiegando le tabelle sviluppate. E naturalmente questo vale anche per i computer subacquei. Lo sviluppo e validazione di un computer subacqueo da parte della US Navy ha richiesto tempi e sforzi veramente notevoli, ed è stata ultimata in tempi relativamente recenti. Analoga situazione per le altre teorie decompressive e tabelle ad esse associate. L’efficacia del lavoro svolto viene misurata cercando di stimare in modo attendibile il tasso di incidenti embolici ad esse associato. Parliamo di stima e non di misura, perché naturalmente il dato che si ricerca va estrapolato da un campione adeguato di immersioni effettuate utilizzando un certo profilo. Non ha alcun senso infatti considerare un certo numero di immersioni effettuate utilizzando un modello decompressivo, misurare il tasso di incidenti che si sono registrati per tale campione, e affermare che questo è il grado di sicurezza del modello utilizzato.
Il punto critico del problema è stabilire le adeguate dimensioni di un campione. Infatti tutte le volte che estendiamo all’intero insieme dei dati teoricamente disponibili le conclusioni relative ad un insieme ridotto, commettiamo un errore. E tutte le volte che sappiamo di commettere un errore, dobbiamo conoscerne bene i limiti. Bisogna perciò stabilire le dimensioni del campione che ci garantiscano che l’errore si mantenga entro limiti accettabili, e con quale probabilità ciò avvenga. Sembra strano parlare di probabilità nella stima ma è proprio così che stanno le cose: la certezza assoluta sulla stima si ottiene solo quando il campione e l’intero insieme da misurare, (detto popolazione), coincidono; ma in questo caso non si tratta di stima bensì di misura. Nel caso dell’incidenza della Patologia da Decompressione in immersione, un evento che si verifica con bassa probabilità, è più difficile stimarlo con percentuale di errore adeguata.
Questo esempio ci chiarirà le idee
| Supponiamo di avere un grande contenitore riempito di fagioli in gran numero, diciamo 10.000, riempito facendo bene attenzione ad inserire un solo fagiolo di colore nero ogni 999 bianchi. I neri sono in totale 10, quindi 1 su 1000, ovvero lo 0,1 % |
Ora consegniamo il contenitore ad uno sperimentatore e chiediamogli di effettuare una stima della percentuale di fagioli neri inseriti nel contenitore basata sul campione. Lo sperimentatore ne estrarrà una parte (nell’esempio 100) e, in base al risultato ottenuto, trarrà delle conclusioni sul totale. E’ molto probabile che prendendo 100 fagioli non ce ne sarà neppure uno nero (la probabilità è infatti del 90%). In tal caso la sua conclusione (errata) sarà:
| 100 fagioli sono estratti e 100 fagioli sono bianchi conclusione: tutti i fagioli sono bianchi per cui la percentuale dei fagioli neri è = 0% |
Siccome i neri sono uno su mille, cioè lo 0,1 %, l’errore sulla stima della percentuale di fagioli neri, cioè la differenza tra valore stimato e reale, è pari a: (0% – 0,1%) = – 0,1%. Questo 0,1 % può sembrare un errore molto contenuto. Se però lo confrontiamo con il valore vero, vediamo che l’errore ha la stessa ampiezza, entrambi valgono 0,1%. E’ un po’ come se stimassimo l’altezza di una persona dicendo che è di 1,8 metri più o meno 1,8 metri.
Supponiamo ora che nel risultato del campionamneto vi sia un fagiolo nero tra i 100 prelevati.
| 100 fagioli sono estratti di cui 99 fagioli sono bianchi e uno è nero conclusione: c’è un fagiolo nero su 100 per cui la percentuale dei neri è = 1% |
Stavolta l’errore rispetto al valore vero di 0,1 % è pari a : (1%-0,1%) = 0,9%, ovvero nove volte il dato reale. In questo caso il precedente paragone con la stima dell’altezza di un uomo cambia: dovremmo dire che l’altezza è di 1,8 metri più o meno 15 metri.

Conclusione
Naturalmente nel nostro esempio i fagioli rappresentano tutte le immersioni sotto test, i fagioli bianchi le immersioni senza incidenti, mentre quelli neri quelle in cui avviene un incidente.
| Come visto nell’esempio è facile ottenere valori non significativi se il numero di immersioni di test è limitato. Si può scivolare facilmente nella sovra o sotto-stima, ovvero nel considerare erroneamente super-sicuro un certo algoritmo, o esageratamente inadeguato un certo altro. Inoltre l’esempio dei fagioli riguarda un insieme vasto, ma limitato, mentre le possibili immersioni tra le quali stimare il tasso di incidenti è teoricamente illimitata. |
Capiamo adesso quanto affrettato e superficiale possa essere il giudizio sulla qualità dell’algoritmo implementato su un computer subacqueo.
Possiamo basare il giudizio sul campione di immersioni che abbiamo sperimentato personalmente? E’ qualcosa che ci da stime attendibili? E, come sempre, quale è il termine di paragone? La sicurezza oppure il tempo medio di decompressione che dobbiamo affrontare? Aver fatto 100 o 1000 immersioni senza riportare incidenti ci può far affermare di avere un modello sicuro? Certamente no. Potremmo essere nel caso dei 100 fagioli estratti tutti bianchi.
L’intervallo di confidenza
Le leggi della statistica ci aiutano con alcune formule specifiche, con le quali è possibile stabilire la dimensione del campione (quante misure occorre fare) per stimare un parametro binario (cioè che può assumere solo 2 valori, nero o bianco, vero o falso, etc), prefissando l’errore massimo ammissibile e l’intervallo di confidenza, ovvero la probabilità che la stima trovata sia realmente entro il limite di errore prefissato.
Se ad esempio la stima di un parametro ha un livello di confidenza del 75% per un errore massimo del 3%, significa che su 100 stime analoghe, in 75, casi si riscontra un errore nel dato stimato inferiore al 3%.
La formula è:
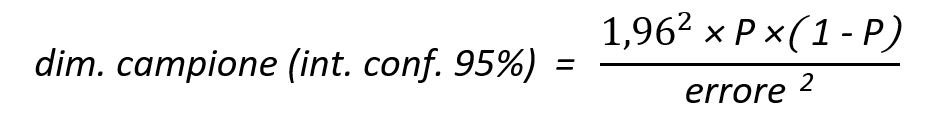
Essa contiene un numerino magico, 1,96, caratteristico dell’intervallo di confidenza del 95%, che si chiama moltiplicatore dell’errore standard, e che dobbiamo prendere per scontato perché la sua giustificazione richiede nozioni di statistica avanzate.
Il valore P invece, detto prevalenza, rappresenta una pre-stima grossolana del dato che stiamo cercando, e per il quale stiamo dimensionando il campione.
Nel nostro caso, supponiamo che la probabilità di incidente embolico per il tipo di immersioni che studiamo sia dell’1%, (un valore conservativamente medio-alto). Ciò permette di ridurre considerevolmente la dimensione del campione quando sappiamo di stimare un dato ben lontano dal 50%. Applicando questa formula risulta che, come c’era da aspettarsi, maggiore è il numero di campioni minore sarà l’errore.
Ecco un esempio pratico:
Ipotizziamo di voler stabilire il numero di immersioni necessario per stimare la percentuale di incidenti da embolia legati ad un certo algoritmo decompressivo.
Innanzitutto fissiamo i requisiti della ricerca:
Pre-stima del dato da stimare (P prevalenza) = un incidente ogni 100 immersioni (0,01)
max errore accettabile sulla stima = 0,5 %, ovvero 0,005
probabilità che l’errore si mantenga entro tale limite, (intervallo di confidenza) = 95%
otteniamo un campione minimo di 1522 immersioni:
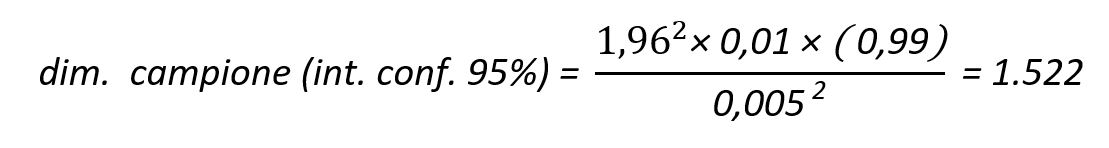
Se volessimo ridurre l’errore di un solo ordine di grandezza, ovvero portarlo allo 0,05 %, (0,0005), la nuova dimensione del campione diviene:
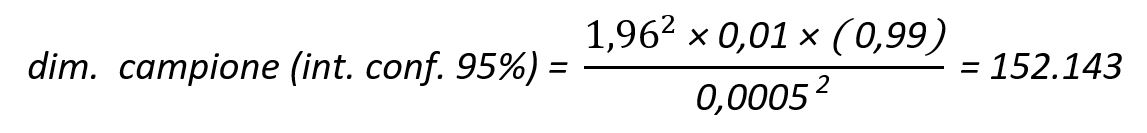
la dimensione aumenterebbe di un fattore 100, portando il valore a 152.143 campioni.
Possiamo dunque basarci sulle esperienze e sensazioni personali per giudicare l’affidabilità di computer e tabelle?
Specialmente per le immersioni a grandi profondità e tempo di fondo, la disponibilità di questi dati o la loro affidabilità può divenire una criticità rilevante del problema. Inoltre, più aumenta la sicurezza dei profili decompressivi sotto test (cioè diminuisce il numero di fagioli neri dell’esempio precedente) e più il campione deve essere esteso perché l’errore percentuale non aumenti.
| La lesson learned è che più aumenta la conoscenza dei fenomeni decompressivi e più diventa difficile misurare con precisione l’efficacia dei nuovi modelli sviluppati, tanto che l’effettivo vantaggio di una nuova soluzione può richiedere molto tempo per venire comprovata (o smentita) dai dati statistici. |
Una prova della sua complessità statistica è il metodo utilizzato per la verifica di affidabilità delle tabelle US NAVY USN57. Esso si basò sull’esperienza maturata nelle fasi di soccorso di un gravissimo incidente aereo avvenuto il 17 Luglio 1996 quando un Boieng 747 della TWA precipitò a largo di Long Island, poco dopo il decollo da New York.. Furono effettuate migliaia di immersioni da parte di centinaia di subacquei civili e militari alla profondità di circa 36 metri, per il recupero delle vittime e di parti del Boeing 747.
Le statistiche maturate in tale campagna di recupero rivelarono un tasso di incidenti piuttosto alto e precedentemente sottostimato, che portò alla emissione, molti anni più tardi, delle nuove tabelle basate sull’algoritmo asimmetrico esponenziale-lineare di Thalmann, denominato VVal-18. Questo modello prendeva in considerazione 18 tessuti con tempi di emisaturazione compresi tra 5 e 240 minuti e intervallo di campionamento ogni secondo. L’assorbimento del gas da parte dei tessuti era di tipo esponenziale mentre la sua eliminazione era di tipo lineare. Il modello risultò esser molto più conservativo.
Un ultimo dato statistico da citare
Tutto questo discorso non vuole generare incertezza e smarrimento, ma recuperare fiducia negli strumenti consolidati, ovvero nei computer subacquei e nelle tabelle decompressive adottate dalle maggiori didattiche subacquee e associazioni sportive di tutto il mondo, evitando per quanto possibile digressioni, aggiustamenti personali, interpretazioni, e soprattutto l’adozione di pianificatori di immersione di non chiara e sperimentata affidabilità che pullulano sul web.
Tutto questo naturalmente è consigliato a subacquei ricreativi e sportivi che non hanno l’ambizione di essere i pionieri di nuovi criteri teorici o sperimentali di l’immersione, specialmente per ciò che riguarda le grandi profondità, alle quali alcune delle già scarse certezze sui fenomeni in gioco divengono ancora più labili.
Sebbene le tabelle siano teoricamente il metodo più sicuro per fare immersioni, esse obbligano sempre a considerare l’immersione come se fosse condotta interamente alla massima profondità raggiunta, e quindi risultano molto penalizzanti per qualunque profilo multilivello, di gran lunga il più praticato in immersioni “turistiche”. In realtà questo margine di sicurezza “improprio” viene pagato (e con gli interessi) da un inconveniente di segno opposto: l’errore umano, che è sempre in agguato malgrado l’utilizzo delle tabelle sia relativamente semplice, e che è invece completamente eliminato dal computer.
| Tutti i test comparativi relativi ad incidenti embolici, effettuati su un elevato numero di immersioni con uso di tabelle o computer subacqueo, fanno pendere nettamente l’ago della bilancia a favore del computer. |
Evidentemente usando le tabelle l’impatto dell’errore umano sul tasso di indicenti è tale da superare l’implicita conservatività legata alla approssimazione del profillo quadro.
Per chi va oltre
Chi invece è un profondista di frontiera, e ha la preparazione, la propensione al rischio, e la determinazione per esplorare nuove strade si trova in una prospettiva completamente diversa, essendo titolato a sperimentare, verificare ipotesi nuove e non consolidate dall’esperienza o dalla statistica. Egli, in un certo senso è disposto ad accettare un maggior rischio proprio nella qualità di collaudatore nella quale si trova. Chi collabora a queste campagne di ricerca non lo fa in modo sconsiderato o superficiale, sa dove può spingersi e calcola con cura i rischi aggiuntivi ai quali si espone. Penso che egli sia il primo a consigliare ad un subacqueo sportivo o ricreativo di fare uso continuativo e fiducioso di computer o tabelle decompressive.
Come concludere?
Direi che non ci sono ne vinti ne vincitori, ma solo una raccomandazione di fondo; abbandoniamo le strade apparentemente facili e le soluzioni preconcette, e rinunciamo ad un pò di orgoglio personale, privilegiando umiltà e desiderio di capire ed approfondire.
Quando si sceglie come salvaguardare la propria sicurezza c’è una sola strada maestra: dare spazio alla forza dei numeri. Ci ha indicato questa strada, sin dal XV secolo, il grande Galileo Galilei, che già al suo tempo seppe affrontare con coerenza e fermezza chi faceva la voce grossa senza avere ragione.
Luca Cicali
PAGINA PRINCIPALE - HOME PAGE

- autore
- ultimi articoli

ingegnere elettronico e manager d’azienda, è un grande appassionato di subacquea ma non è un professionista del settore. E’ autore di Oltre la curva, un testo di subacquea diventato in breve un best seller per tutti gli appassionati.